

You may be looking at your 2026 budget and trying to plan your Identity Governance and Administration (IGA) priorities. If you’re a few years into your IGA deployment, you may be finding it increasingly challenging to keep attention and executive support, while still facing a large backlog of applications that are not covered. Or, you are looking to implement IGA for the first time as a strategic initiative and are trying to prioritize where to start. I know this article is mainly focused on the next evolution but want to take a step back and focus on some groundwork and IGA deployments.
Most IGA deployments suffer the same fate. Not due to effort or technical abilities, but due to expectations. I’ve been in many rooms consulting on IGA and the automation, cost savings, compliance capabilities it will bring. A year or two into the deployment, leadership starts asking when they are going to realize the benefits of the project given the elongated deployment cycle of a typical IGA deployment. But an IGA deployment is highly dependent on multiple critical factors: Data, Application Support, and Resources. If you’re missing or lack any of those critical factors, then you’re going to have challenges from the start and leadership will change focus, causing the IGA deployment to become stagnant.
To address this, everyone I talk to planning or trying to right-size their existing IGA deployments, I tell them to put your target applications / integrations into three general buckets.
- OOTB / Common: These are going to be applications that have ootb connectors or are very common and can quickly get onboarded and provide rich visibility and functionality to your IGA deployment. These might even be part of your core infrastructure and risk profile for the organization. This typically represents maybe 20-30% of your total target application coverage.
- Generic Frameworks / API Accessible: These are the applications that have rich APIs or SCIM that can be onboarded into your IGA deployment through use of generic scripting frameworks / connectors or standards. This usually represents roughly 50% or your target application coverage.
- Technical / Operational Limitations: These are the applications that have no API, developer has left the organization so is no knowledge, or is legacy supported so may (and probably) never would have a connector available to integrate into the IGA. This typically represents about 20% of your target application coverage.
The diagram below outlines how this can be represented in terms of buckets with sliding scale of Cost, Complexity, and Level of Effort.
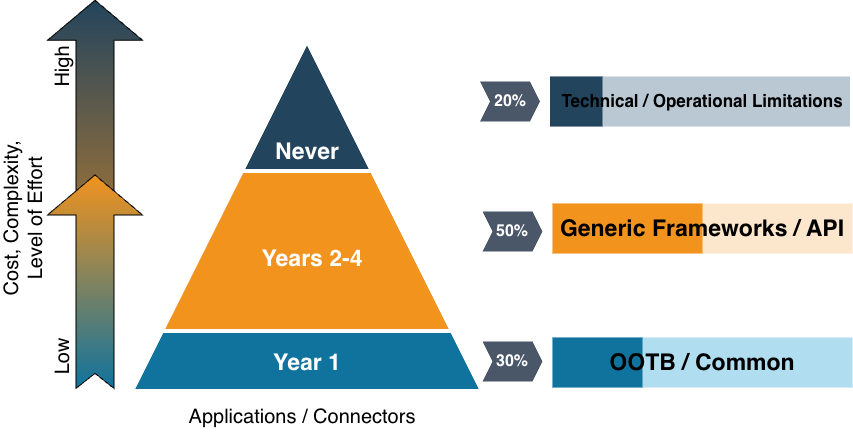
Given these buckets, I typically work with people and let them know they should take buckets 2 and 3 and immediately push them into a Service Management (Manual Fulfillment) style of integration. What this really means is you represent the applications in IGA, but handoff the fulfillment and work to a ticketing system for owners to work on. The OOTB / Common bucket you’ll get done in roughly year 1 given the speed and velocity you can onboard the applications. For Bucket 2, you can move those over time to automated connectors based on priority and resources.
This approach gets you coverage of your applications quickly so can show leadership the return on investment and continue to receive support. But, the challenge with this approach, it is still resource intensive which is counter to the original intent to reduce resource need given the automation. Ultimately, even with this, you end up with a lot of applications onboarded (which is good) but will run into the support stagnation problem. In my experience, usually around year 2 of an IGA deployment you run into this.
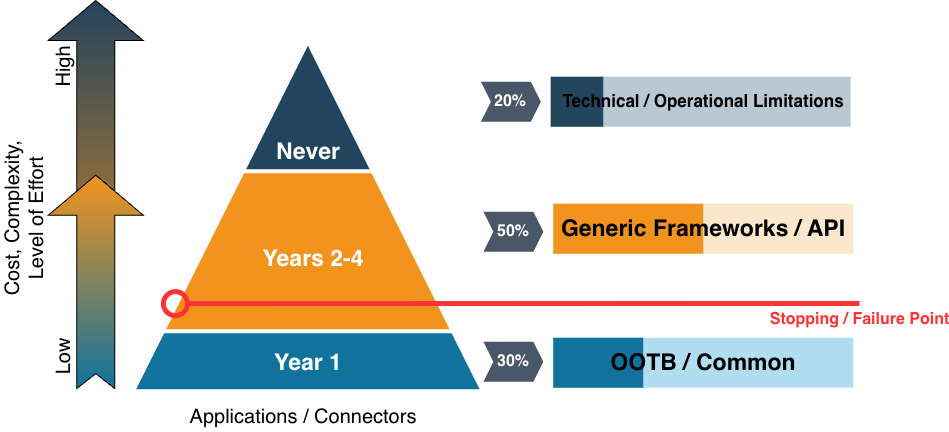
At this point, this is where I start getting calls about evaluating alternative IGA products or ways to accelerate the automation and capabilities.
But, changes are coming to address this challenge.
AI and IGA
You may have read the title of this blog and thought AI is the revolution that is coming. In a sense it is, but not in the context many may think it is. A lot of the AI development to date is focused on the data analysis and recommendations coming out of IGA. You see things like role mining, recommenders, etc. that are ridiculously helpful and cool, but suffer from the same issues as above. You are providing insights on flawed or incomplete data. This leads to AI bias issues. If you look at the below diagram, and based on the examples above, you are getting feedback from models based on maybe 30-40% of the data for the organization.
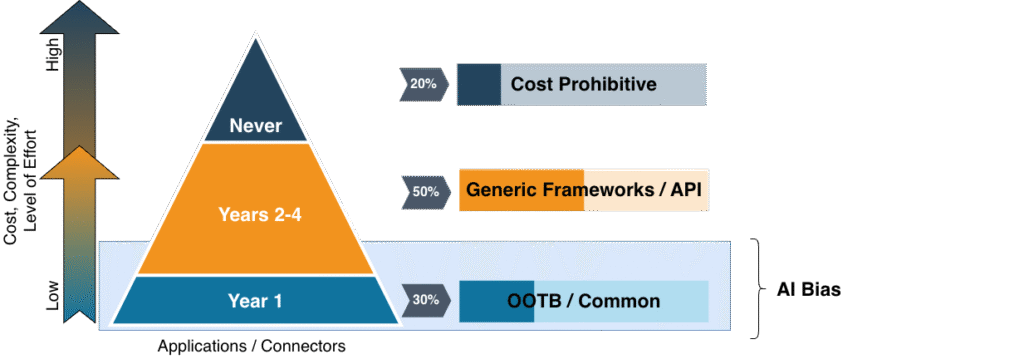
AI, IGA, and the Revolution
The real force multiplier and revolution for IGA I see coming is in the application connector and integration space. Vendors like StackBob (https://www.stackbob.ai/) and Cerby (https://www.cerby.com/) are coming into the market and using Agentic AI to automate application integrations. You may look at these and think this is just click automation / RPA, but it is so much more than that. The challenge with RPA and click automation is they can be fragile to change and have challenges with getting data back to the IGA platform for aggregation and reconciliations. A true Agentic AI approach to this can learn application patterns, analyze data (e.g. user lists, entitlements, etc.) and provide structured responses to queries, not just task responses. What you end up with is a set of OOTB connectors for your core platforms then a single connector for everything else in your environment (see below).
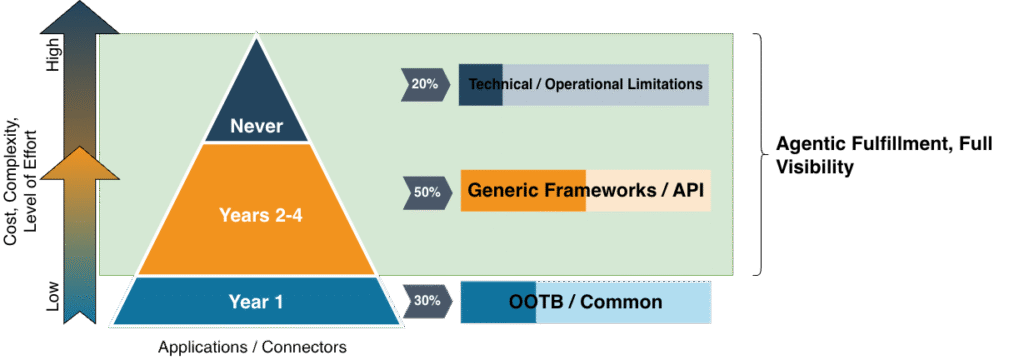
Once you have this in place, ongoing maintenance and onboarding can be as simple as just inviting an agent into a new application and this will start feeding user information into the IGA platform.
Now, with coverage of OOTB, and everything else (with rich user data), your AI capabilities will have visibility into your entire organization to make informed, complete, recommendations and decisions.
High Visibility, High Noise, Low Effect
One of the questions I get asked a lot as more applications are onboarded, how do you make certifications and attestations more effective and relevant. As managers and applications owners see more, and IGA teams push campaigns with more data, we’re almost creating too much noise to catch and address actual risk. The direct response here is to make the certifications and attestations more relevant through risk and usage data. This is one of the other features of this Agentic AI approach that is going to enhance the IGA deployment. Agents doing provisioning and monitoring usage can also be used to report usage telemetry back into IGA platforms. This can enhance certifications by highlighting residual or stagnant risk based on usage data showing reviewers where they can clean up access. If someone has been provisioned a high cost or risk application, but never uses it, then during a periodic review, this can be flagged for additional review and cleanup. Applications like Aceiss (https://www.aceiss.com/) and StackBob (https://www.stackbob.ai/) are capturing this data and can be used to enrich usage and risk telemetry in your IGA platform.
Final Thoughts
I’ve been working in the Identity space for a long time and have consistently run up against the challenges in this article. Most IGA deployments reasonably are 3-5 years (planned) and can take more since they are the basis of your Identity Security program. I am consistently talking to leaders about prioritizing and managing onboarding of applications. In 2025, the vendors are addressing this as a priority given the SailPoint acquisition of Savvy to help with discovery and onboarding. But, where I see the big acceleration and realization coming in 2026 is how vendors are going to start really giving the any application, any time approach to application onboarding with minimal effort by implementation and engineering teams.




