
Over the last few months of 2025, I had several conversations with CISOs and Identity teams about AI and IAM use cases. Teams are rapidly trying to support their organizations as they adopt or enable AI in different areas and are struggling with how to secure it, use it to automate Identity tasks, and translate capabilities into business use cases. Given the wide range of products, capabilities, and new feature releases from vendors, I wanted to go over how I break this down for leaders and teams and where I see a pending wall we’re approaching and how innovation is going to address this.
For any Identity program, I always go back to the three main pillars every Identity program should have. This is your Identity Governance (IGA), Access Management (AM), and Privileged Access (PAM). This forms the foundation of the Identity program and has different interactions with user and AI use cases. In any planning or discussion, I always start with the foundational pillars of the program since each is going to play different roles in the overall AI strategy for the organization.

With the identity pillars established, I usually break down the AI use cases into three main buckets, or focus areas, organizations and teams need plan for. This isn’t specific to any pillar since they all kind of rely on each other, so, have dropped in the functional AI areas as an underlay on the IAM pillars. But, as I’ll discuss a bit further down, the AI buckets do have an order of precedence and quality when building things out.
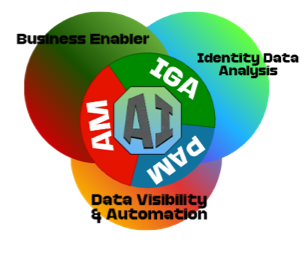
The main areas for AI teams must recognize and plan their IAM infrastructure are:
- The Business Enablement: This is probably one of the biggest areas we see in the vendor space, and this centers around how is Identity supporting business to access resources, enable agents, support delegation and secure authentication, authorizing access, etc. If you look at this directly, this is a lot of the same use cases for normal users, but different scale and level of automation. So, if you’re user use cases are not solid, enabling AI is going to be orders of magnitude more challenging.
- Some of the major innovations in this space are around the agent discovery, agent registration, authentication and authorization, etc.
- Identity Data Analysis [& Outcomes]: Identity infrastructure has mountains of data. Whether it is application data, governance data for role and access models, risk data based on privileges and entitlements, or general usage data and policies. All this data is primed for the capabilities of AI to derive outcomes that can be used for automating things like roles, access reviews, step up authentication, authorization, etc. I usually break this down into two main buckets.
- Entitlement Decisions and Automation: This is primarily an IGA or PAM use case, but how do we analyze and identity populations, roles, access, automate approvals, identity risk, etc. Things like SailPoint and Saviynt are doing a lot here, but you have vendors like Lumos that are coming and accelerating some of this to speed up analysis and decisions.
- Transactional Outcomes: This is primarily an AM and PAM use case, but centers around analyzing historical and current risk data for a transaction (e.g. high-risk login, high risk user, etc.) and changing the flow of a transaction (e.g. adding additional MFA, restricting access, etc.).
- Data Visibility & Automation: This is probably one of the least developed areas, but most critical opportunities for AI in Identity. All the AI capabilities have a foundational need; this is visibility into target systems and identities to be able to make informed decisions. You’re starting to see agentic IGA platforms address this need by using agents to breakdown connectivity barriers and gather data to enrich platforms and automate traditionally manual tasks and flat files. See more below how this impacts things in the AI funnel. 2026 will see this area grow with new capabilities hitting the market.
If you’re looking to build out an AI strategy for your Identity team, make sure you plan for all the above and your current Identity infrastructure can handle the load and use cases needed.
The Pending Risk Wall?
One of the first questions I always ask people when they’re implementing some of the data analysis components is how much coverage they have in their IGA infrastructure. Most organizations I talk to, and think is about industry standard at this point for success, have ~30-40% of their target applications integrated into IGA. If you’re going to allow AI to analyze and make access recommendations for users but only allow it to see and make recommendations (or decisions) based on 30-40% of the environment, you’re going to run into risk issues. At some point, an auditor is going to ask why someone has access to an application. If the response is ‘AI said they should based on its analysis of the environment’, then they’re (or at least they should) ask how it came to that conclusion. If you cannot answer that or show the complete picture, this is a risk.
To show what I mean by this, here is a [small] example of a target department and set of applications. Now, this is a super simple example, but you have four users, five applications, and IGA platform controlling access to three of the applications. Users 1-3 have access to all applications (even though IGA doesn’t know about 4 and 5). User 4 has access to just application 1. BUT all users are in the Accounting department.
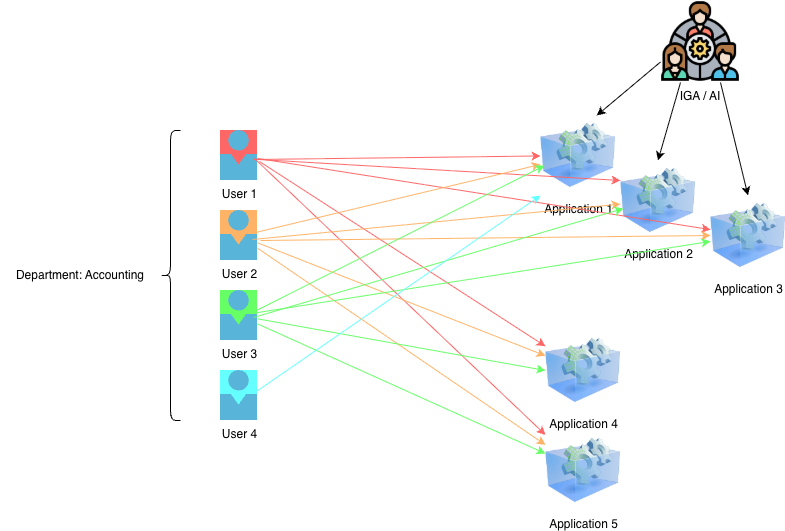
A typical analysis of this picture is going to identify the population for Accounting department and access across applications 1-3. This would result in a role possibly being recommended for applications 1-3 for the Accounting department.
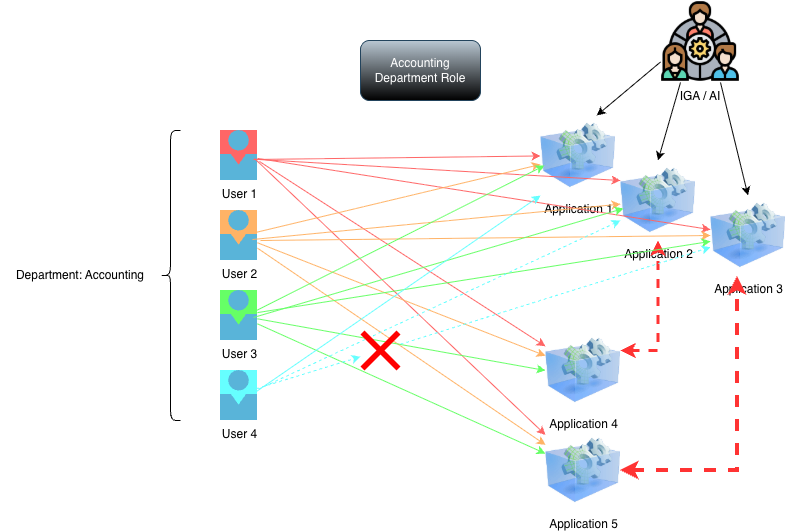
With this recommendation, User 4 would be granted access to applications 2-3. But here is the issue, application 2 is linked to application 4, and application 3 is linked to application 5. What if 4-5 are training, anonymization, other security overlays for applications 2 and 3, User 4 may have just been granted access to something they should not be granted given the analysis did not know of applications 4-5? This is where Risk and potential Bias come in to play and can cause compliance issues for organizations.
Think of AI and IAM as a progressive data analysis and enrichment. As you start with source raw data on the left, it moves through the pipeline of AI areas and gets progressively refined and usable.

A breakdown in the initial raw data can cause bad analysis and outcomes as it moves through the pipeline.

Why is this important?
I bring this up because as we evaluate AI technology and use cases, we also need to be very cognizant of how we are getting and using the data to present it to our customers (the business enablement). As organizations look to start adding Ai capabilities, you need to look at all the main areas of AI and IAM. I am reordering based on the above in terms of focus and quality to derive informed outcomes and use cases.
- Visibility and Automation: Look at the application environment and business policy. How are you aggregating target applications, making decisions on access and outcomes? Do you have all the applications in your IGA? Do you need to look at emerging technology like Agentic IGA to augment and enrich existing IGA platforms? Important thing here is to allow your AI (in bucket 2) to have the complete picture so can perform the analysis it needs.
- Identity Data Analysis: Once you have the complete picture, enrich the analysis with guardrails, business policy, risk, etc. so it can give you recommendations. Using the example above, applications that have restrictions (e.g. training, sensitivity, etc.) should be annotated with such so recommendations have the complete picture. Usage and transactional data (e.g. risk-based logins) should have enough history, work locations, data and application sensitivity, to make decisions and outcomes to protect applications and lower user friction.
- Business Enablement: Once you have the data, publish services to the organization to enable them to use Identity in their AI use cases. Enable features like agent registration, MCP registries, AI gateways, user-to-agent delegation, etc. with the infrastructure and source data you must allow the business to accelerate their adoption in a secure, informed, way.
The market and standards are moving at a rapid pace right now to build out guidance and tooling in each of the above buckets. As you look to implement infrastructure in 2026 and beyond, make sure you plan for each of the AI buckets which will enable a successful program and usage in your organization.




